文字コードとは
文字コードって何?
パソコンを開けば、あたりまえですが、数字、アルファベット、漢字、平仮名・片仮名様々な「文字」が表示されます。
御存知のとおり、コンピュータは情報をビットで管理します。ビットには1か0の2つの値しか入りませんので、コンピュータは「文字」をビットの0と1の組み合わせで理解しています。
しかし、人間は文字を「11101100」のように見せられても理解はできません。なので、「どの文字をどのビットの組み合わせで表現するか」を決めておき、文字をコンピュータが識別できるようにしています。この、各文字に割り当てられる、ビットの組み合わせを定めたものが「文字コード(Character Encoding)」です。
これだけだと、非常にシンプルに感じると思います。実際に仕組み自体はシンプルです。しかし、世の中には様々な言語・文字があり、中には漢字のように膨大な数を有するものもあります。
情報技術は徐々に発展し、世界中に普及していきましたが、その過程で様々な種類の文字コードが生まれました。初期のコンピュータは扱える情報量も現在と比べると非常に少なく、ハード上の制約などもあってか、メーカーが独自に策定・拡張するケースもありました。そもそも、文字コードを統一する動機も昔は少なかったでしょう。このような経緯もあり、現在は様々な文字コードが存在しています。
文字化けの原因
ファイルを開いたり、Webページを開いた時に「文字化け」を経験したことがある方は多いと思います。これは、ファイルを作成した時の文字コードと、ファイルを読み取る時(テキスト・エディタでファイルを開く、ブラウザでHTMLファイルを開く、等)の文字コードが異なる場合に発生します。
同じ文字でも、文字コードの種類が異なれば、異なるビットの組み合わせで表現されます。例えば平仮名の「あ」はShift-JISという文字コードでは「10000010 10100000」ですが、UTF-8では「11100011 10000001 10000010」となります。ビットの並びどころか、数からして異なります。これが文字化けの主な原因です。
プログラミングを行う上で、特にWindowsを使っている方は必ず一度は文字化けを経験すると思います。そのため、文字化けに対処できるように、少なくともファイルを作成するとき・ファイルを利用するときに文字コードを指定する方法は理解する必要があります。
もちろん、文字コードの種類を覚えたり、ビットの組み合わせを覚えたりする必要はありませんので、そこまで気負わなくても大丈夫です。
良く使われる文字コード
UTF-8
上述のとおり、文字コードは様々な種類があります。乱立した文字コードを統一すべく、「世界中の文字を使えるように」という思想のもと、Unicodeという規格が生まれました。UTF-8は、Unicodeの文字符号化形式の1種です。他にも、UTF-16等があります。
その思想のとおり、日本語を含め世界中の文字が扱えます。そのため、様々な国・デバイスで利用される可能性のあるファイルは、なるべくUTF-8を使う風潮になっています。Webページに関しては、UTF-8を使うのがルールです。多くのプログラミング言語でも、デフォルトはUTF-8で解釈されるようになっています。
後述するShift-JISと比べると、UTF-8は日本語を表現するのに3Byte使います(Shift-JISは2Byte)。そのため、容量を多く使うのがデメリットです。しかしながら、プログラミングをする上では、基本はUTF-8を使うケースがほとんどです。プログラムのソースだけでなく、プログラムで読み取るファイルも、基本はUTF-8で作成するようにしましょう。
UTF-16
Unicodeの文字符号化形式の1種です。UTF-8ほど使われませんが、Windowsの一部の機能では使われています。プログラミング関係でいうと、WindowsのPowerShellはUTF-16が使われていることは、把握しておいたほうが良いかもです。
Shift-JIS
日本語を表現するための文字コードです。日本人には馴染みが深いと思います。現在はなるべくUTF-8を使うようになっているようですが、昔のシステムとの互換性を保つために、Windowsの一部機能では標準で使われる文字コードです。
日本語は2Byteで表現されるのが特徴です。UTF-8より少ない容量で表現できます。そのためか、Windowsテキストファイルを作ると、Shift-JISで作成されていることが多いです。
「プログラムでテキスト・ファイルを開いたら、日本語が文字化けする!」の原因は、大体はテキスト・ファイルがShift-JISで作成されていることが原因です。それをプログラム側がUTF-8で解釈しようとするため、文字化けが発生します。
少しややこしいのですが、特にWindows環境では、「Shift-JIS」というと「CP932」のことを指します。「CP932」は、Shift-JISをMicrosoft社が拡張したものです。
Windowsのコマンド・プロンプトで使われる文字コードは、Shift-JIS(CP932)となります。
ASCII(アスキー)
最も歴史が古い文字コードでしょうか。数字、記号、アルファベットを7ビットで表現します。日本語は表現できません。明示的にASCIIでエンコードすることは稀かもしれません。しかし、UTF-8等、ASCIIと互換性がある(ASCIIで表現できる文字は同じビットで表す)文字コードも多いので、紹介します。
文字コードを指定する
テキスト・ファイルを保存するときに、文字コードを指定する方法を紹介します。だいたいどのエディタでも同じです。
プログラムからファイル読み書きを行う際の文字コードの指定方法は、プログラミング言語次第となるため、ここでは割愛します。
サクラ・エディタの場合
「ファイル(F)」のメニューを押し、「名前を付けて保存(A)」を選択します。
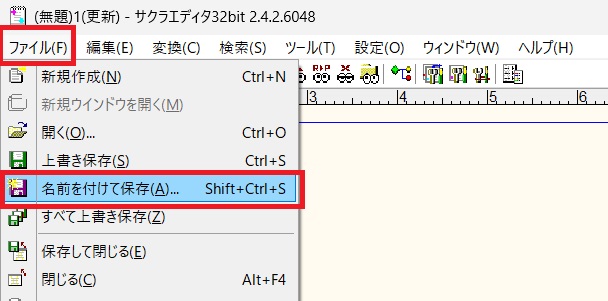
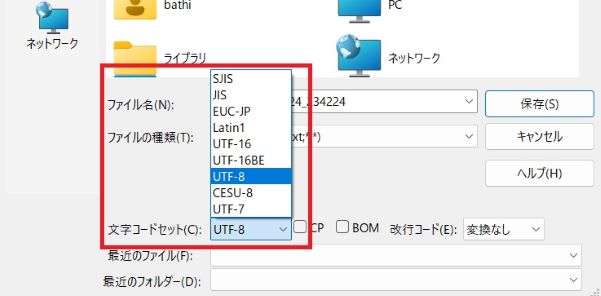
「名前をつけて保存」の子画面が開きます。下の方にある「文字コードセット(C)」のプルダウンを選択すると、文字コードの一覧が表示されます。後は、文字コードを選択して「保存(S)」をクリックすればOKです。
VSCodeの場合
画面の右下にある、文字コードが表示されている箇所をクリックします。画像の場合、開いているファイルはUTF-8で保存されているため、「UTF-8」と表示されています。

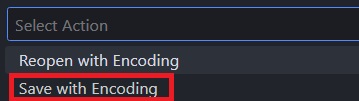
画面上部のバーの部分(コマンド・パレットと呼びます)にメニューが表示されるので、「Save with Encoding」を選択します。私は日本語パッチを入れていないので英語で表示されています。
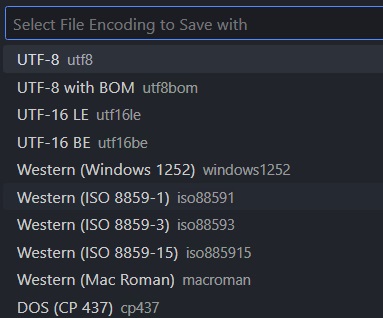
文字コードの一覧が表示されます。変換先の文字コードを選択します。後は、「CTRL+S」で保存すれば変換されます。保存しないと適用されないので注意です。
余談:エンコーディングとデコーディング
「文字」を文字コードに従ってビットの組み合わせに変換することを、エンコーディングといいます(そもそも、「文字コード」はCharacter Encodingの訳語です)
エディターにはテキストファイルを保存する時に、通常は文字コードを選択するオプションがありますが、「エンコーディング」とか「エンコード」と表現されていることが多いです。
プログラミングでも、ファイルの読み書きを行う時、encodingといった用語を使って文字コードを指定することが多いです。そのため、ただの用語ですが覚えておいて損はないです。
デコーディングは、逆にビットの組み合わせを「文字」に変換することです。「エンコーディング」よりは見かける機会は少ない気がします。というか、「文字コード」、「エンコーディング」、「デコーディング」をあまり区別せずに単に「エンコーディング」と呼ぶことが多いと思います。「そのファイルのエンコーディングは何?(文字コードは何?)」といった具合に。