npmの巨大なエコシステム、unifiedについて調べました
はじめに
このサイトはもともと素のReact.jsで作っていたのですが、リンクをページ単位で貼れないのが不便だったのでNext.jsに移行しました。 移行の際、mdファイルをhtmlに変換する処理を、markdown-to-jsxというパッケージからremarkに変更しました。
Next.jsの公式サイトのチュートリアルで、remarkを使ってmdファイルからブログ記事を静的ビルドする方法が紹介されているので、remarkについてご存じの方も多いのではないでしょうか。
その中で、mdからhtmlに変換する処理が以下のように記述されています。
import { remark } from 'remark';
import html from 'remark-html';
async function getPostData(id) (){
/*一部省略*/
const processedContent = await remark()
.use(html)
.process(matterResult.content);
const contentHtml = processedContent.toString();
/*一部省略*/
}
何が行われているのかよく分からかったのですが、もともと使っていたmarkdown-to-jsxが静的ビルドでは利用できないということもあり、チュートリアルのこの内容を信じてそのまま実装していました。
ただ、後からGitHubのmdファイル形式(GitHub-Flavored-MarkDown)に対応させたり、コードのハイライトを入れたり機能追加していき、 上記に該当する部分が膨れ上がってきました。
import { remark } from "remark";
import html from "remark-html";
import remarkPrism from "remark-prism";
import remarkGfm from "remark-gfm";
async function toHTMLString(md: string): Promise<string> {
// remarkGfm -> githubのmd形式に対応したparser。
const processed = await remark()
.use(remarkGfm)
.use(remarkPrism)
.use(html, { sanitize: false })
.process(md)
return processed.toString();
}
すでにremark-prismとかremark-なんとかがいっぱい出てきてややこしいですが、ここからさらにhtmlのサニタイズを行う処理と、remark-htmlをremark-rehypeに書き換えることを予定しています。これ以上、よく分からないまま機能を追加していくのも気持ちが悪いので、一回ドキュメントを見て大枠を把握しようとしたのですが、予想外に興味深い内容だったのため記事にすることにしました。
前提
package.jsonの設定について
unified関連のパッケージはNode.jsのESMのみ対応のパッケージが多いです。そのため、package.jsonに"type":"module"を追加しておきます。
{
"name": "unified",
"version": "1.0.0",
"description": "",
"main": "index.js",
"type": "module",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"keywords": [],
"author": "",
"license": "ISC",
}
セキュリティについて
マークダウン自体にHTMLのタグを埋め込むことが可能です。HTMLに変換することは、使い方にもよりますが、クロスサイトスクリプティングの可能性もあり、危険な操作と言えます。
マークダウンをHTMLに変換する例示が出てきますが、試される場合は自分もしくは信頼できる人が作成したmdファイルを利用してください。
unifiedとは
remarkのnpmリポジトリを見ると、「マークダウンのインプットをパースし、マークダウンをアウトプットとしてシリアライズするunifiedのプロセッサです。」と記載されています。
次に、remark-gfmのnpmリポジトリを確認すると、「GitHubがMDに加える拡張機能を有効にする、unified(remark)のプラグインです。」と記載されています。
いずれも、unifiedが出てきますね。unified自体もnpmのパッケージになっています。unifiedのnpmリポジトリには以下のように記載がされています。
unified is an interface for processing text using syntax trees. It’s what powers remark (Markdown), retext (natural language), and rehype (HTML), and allows for processing between formats.
マークダウンとかHTMLのようにフォーマットの決まったテキストを、プログラム中で処理出来る形(syntax tree)にした上で、処理を加えたり、フォーマット変換が出来るようにするための機能とのことです。また、unified自体はインタフェースで、マークダウンの処理はremark、HTMLの処理はrehypeといったように、フォーマット別のパッケージが実装がされていることも読み取れます。
マークダウンにJSXを埋め込めるMDXや、GatsbyやPrettierといったフレームワークにも使われているようです。
少し話がそれますが、現時点(2023年2月)でWeekly Downloadsが10,000,000(!!!)を超えています。表示がバグってるんじゃないかと思うレベルですが、、、おそらく上記のremarkやrehypeのように、unifiedを実装したパッケージのdependencyとしてインストールされているのも一因かと思います。いずれにしても、巨大で活発なエコシステムが展開されていることは間違いないでしょう。
そして、VercelやCoinbaseのようなユニコーン企業や、American Express等がスポンサーになっています。
unifiedの概要
npmリポジトリにある図が分かりやすいので引用します。なお、図中のTransformersやParser等の用語は、あくまで概念として捉えておくのが良いと思います。unifiedを実装している、個別のパッケージ内での呼び方は異なる場合もあります。
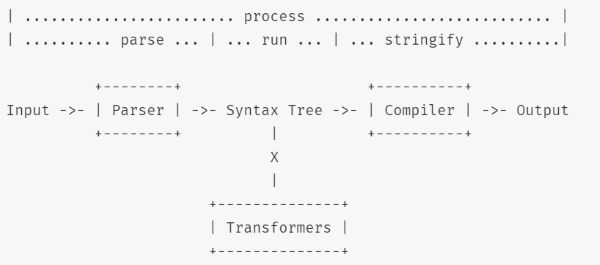
解説用の、mdファイルからhtmlに変換するスクリプトです。
import { unified } from "unified";
import remarkParse from "remark-parse";
import remarkRehype from "remark-rehype";
import rehypeStringify from "rehype-stringify";
const mdTest = `
# こんにちわ、世界
## mdファイルをhtmlに変換します。
これはpタグに囲まれるでしょう。`
async function markDownToHTML(mdString) {
return await unified()
.use(remarkParse)
.use(remarkRehype)
.use(rehypeStringify)
.process(mdString)
}
const file = await markDownToHTML(mdTest)
console.log(file.toString())
実行結果です。
<h1>こんにちわ、世界</h1>
<h2>mdファイルをhtmlに変換します。</h2>
<p>これはpタグに囲まれるでしょう。</p>
Syntax Tree
図の真ん中にあるSyntax Treeは、マークダウンのようなテキストをプログラムが分かるように変換したものです。マークダウンならmdast、HTMLならhastといった具合に、ファイルのフォーマットごとに定義されています。
ちなみに、Syntax Treeを処理できるプログラムのことをpluginと呼びます。
npmパッケージを自作でもしない限り、Syntax Treeを直接いじることはないと思います。用途に応じたpluginがnpmパッケージとしてリリースされているので、基本はそれを使っていくことになります。テキストをいったんプログラムが理解できる形に変換をし、そこに処理を加えていくイメージがあれば、使う分には問題ありません。
Parser(parseフェーズ)
Input(テキスト)をSyntax Treeに変換するのがParserです。
ちょっと強引な例えかもしれませんが、Javascriptで言えば、JSON.parse(JSON文字列→Javascriptのobject)みたいなイメージでよいと思います。
Syntax Treeに対応したparserを使う必要があります。マークダウンならremark-parse、HTMLならrehype-parseと、専用のパッケージがちゃんとリリースされています。例示のスクリプトでは、マークダウンのテキストをSyntax Treeに変換するため、remark-parseを使っています。
Compiler(stringifyフェーズ)
Syntax Treeからテキストに変換するのがCompilerです。JSON.stringify(Javascriptのオブジェクト→JSON文字列)のイメージです。 こちらも、remark-stringify(マークダウン)、rehype-stringify(HTML)のようにSytax Treeごとのパッケージが準備されています。例示のスクリプトではrehype-stringifyが該当します。
Transformers(runフェーズ)
図のSyntax Treeの下にあるTransformersは、Syntax Treeを別のフォーマットのSyntax Treeに変換するプログラムです。例示のスクリプトでは、remark-rehypeが該当します。このパッケージはmdast(mdのSyntax Tree)をhast(HTMLのSyntax Tree)に変換してくれます。
また、フォーマットの変換だけでなく、コード部分のハイライト等、Syntax Treeを操作するpluginもTransformersに分類されます。
process
parse、transform、compileの一連の処理がprocessとして紹介されています。ただの用語ではあるのですが、例えばremarkはドキュメントで以下のように紹介されています。
a unified processor with support for parsing markdown input and serializing markdown as output by using unified with remark-parse and remark-stringify.
「remark-parseとremark-stringifyを使った、マークダウンのインプットと出力をサポートするunifiedのprocessor」と紹介されていて、parserとcompilerを兼ねたパッケージであることが分かります。
unified関連のパッケージを使うときは、それがparserなのか、compilerなのか、それとも両方兼ねたprocessorなのか、はたまたtransformerなのか、意識する必要がありそうです。
まとめ
unifiedでの処理は以下の流れで行われます。()内は例示のスクリプトの該当箇所です。
- テキスト(マークダウンとか)をSyntax Treeに変換(remark-parse)
- Syntax Treeを操作・変換。(remark-rehype)
- Syntax Treeからテキストに変換(rehype-stringify)
API
簡単な使い方を紹介します。
processor
まずはprocessorを初期化する必要があります。
import { unified } from "unified";
const processor = unified();
remarkやrehypeのように、processorとして実装されているパッケージであれば、以下のように初期化することも出来ます。
// remarkの場合
import {remark} from "remark";
const processor = remark();
remarkのドキュメントを見ると「HTMLとか別のフォーマットに変換するなら、remark()じゃなくてunified()で初期化したほうがいい。そのほうがpluginが色々使えるから」と記載されていました。一方で、remark()で初期化してremark-rehypeでHTML変換するサンプルをたくさん見かけるので、動きに大差はないのかもしれませんが、、、。
processor.use()
processorに、parserとかtransformerとかcompilerを登録する関数です。返り値はprocessor自身なので、.use().use().use()とチェーンが可能です。
あくまで登録だけで、実行はこれだけではされません。Express.jsのミドルウェアの登録みたいですね。
import { unified } from "unified";
import remarkParse from "remark-parse";
import remarkRehype from "remark-rehype";
import rehypeStringify from "rehype-stringify";
const processor = unified()
.use(remarkParse)
.use(remarkRehype)
.use(rehypeStringify)
processor().process()
.use()で登録した処理を実際に実行する関数です。非同期で実行されます。同期版は.processSync()があります。
戻り値は、VFileという型になります。VFile.toString()を呼べば、文字列を抽出出来ます。
import { unified } from "unified";
import remarkParse from "remark-parse";
import remarkRehype from "remark-rehype";
import rehypeStringify from "rehype-stringify";
const file = await unified()
.use(remarkParse)
.use(remarkRehype)
.use(rehypeStringify)
.process("# Hello,world")
console.log(file.toString());
実行結果
<h1>Hello,world</h1>
mdファイルからhtmlファイルへの変換を実装してみる
それでは、実際にマークダウンをHTMLに変換して出力するスクリプトを実装してみます。完全なHTMLファイルとして出力するため、rehype-documentというpluginを使ってみます。
処理の流れは以下の通りです。
- remark-parseでマークダウンをparse
- remark-rehypeでhast(HTMLのSyntax Tree)に変換
- rehype-documentで完全なHTML化
- rehype-stringifyでcompile
パッケージのインストール
npm i remark-parse remark-rehype rehype-document rehype-stringify
unified自身は、remark-parse等と一緒にインストールされるので省いています。
Inputのマークダウン
test.mdの名前で、以下の内容を保存しておきます。
# Unifiedテスト
## remark-なんとか rehype-なんとか
似た名前のパッケージがたくさんあるからややこしい、、、
- remark-parse ???
- remark-rehype ????
- rehype-parse ????
```python
import os
def test():
print("Hello,World!")
```
OutputのHTMLに適用するCSS
せっかくなので出力するHTMLに適用するCSSを準備します。main.css*の名前で、スクリプトと同じ階層に置いておきます。
h1 {
text-align: center;
background-color: pink;
}
pre {
background-color: #333;
color: #f1f1f1;
font-family: inherit;
padding: 1rem;
}
いざ実装
出力するHTMLファイルの名前はtest.htmlにしておきます。
import { readFileSync, writeFileSync } from "fs";
import { unified } from "unified";
import remarkParse from "remark-parse";
import remarkRehype from "remark-rehype";
import rehypeDocument from "rehype-document";
import rehypeStringify from "rehype-stringify";
// test.mdを読み取る
const md = readFileSync("./test.md", { encoding: "utf-8" })
// rehypeDocumentのオプション
const docOpt = {
title: "unifiedテスト", // htmlのtitleタグ
language: "ja", //<html lang="ja"></html>
link: [{ rel: "stylesheet", href: "./main.css" }] // css
};
// process
const vfile = await unified()
.use(remarkParse)
.use(remarkRehype)
.use(rehypeDocument, docOpt)
.use(rehypeStringify)
.process(md)
// test.htmlとして出力
writeFileSync("test.html", vfile.toString());
出力されたhtmlをブラウザで開いて確認します。アドレスバーとかお気に入りはボカしています。コード部分はシンプルな見た目ですが、別のpluginを使えばハイライトすることも可能です。
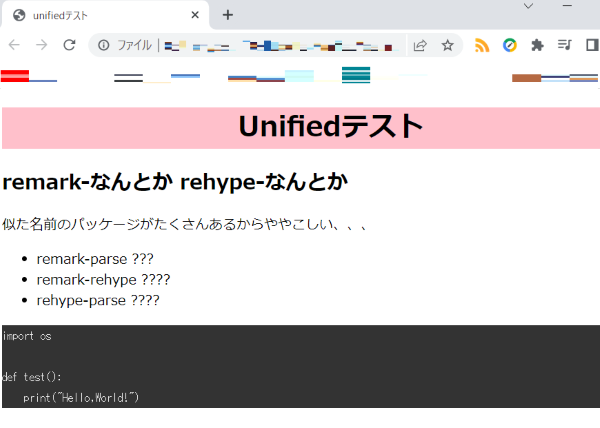
出力されたHTMLのソースです。ここまでやってくれると便利ですね。
<!doctype html>
<html lang="ja">
<head>
<meta charset="utf-8">
<title>unifiedテスト</title>
<meta name="viewport" content="width=device-width, initial-scale=1">
<link rel="stylesheet" href="./main.css">
</head>
<body>
<h1>Unifiedテスト</h1>
<h2>remark-なんとか rehype-なんとか</h2>
<p>似た名前のパッケージがたくさんあるからややこしい、、、</p>
<ul>
<li>remark-parse ???</li>
<li>remark-rehype ????</li>
<li>rehype-parse ????</li>
</ul>
<pre>
<code class="language-python">import os
def test():
print("Hello,World!")
</code>
</pre>
</body>
</html>
最後に
remark-parseとか、rehype-parse等、似た名前のパッケージが多く、どのパッケージを選べば良いのか、初めて利用した時は理解できませんでした。しかし、parse、transform、compileの流れを頭に入れておけば、やりたいことに応じてフェーズごとにパッケージを選ぶだけです。思いのほか気軽に使うことができるのが、今回調べて分かりました。
npmのダウンロード数からも分かるように、unifiedには大きなエコシステムがあります。例えば、remarkのpluginだけでもこれだけ紹介されています。このサイトもマークダウンから作成しているページが結構あるので、今後もいろいろ試していきたいです。
mdastのようなSyntax Treeの仕様もしっかりドキュメント化されているようなので、余力があればどういう仕組みになっているか見ていこうと思います。