SQLの基礎の基礎
はじめに
SQLは関係データベースのデータの作や定義に使われる言語です。
SQLはISO(国際標準化機構)で規格化されているため、関係データベースはOracle、Postgre、SQLite、MySQL様々な製品があるものの、(基本的には)同じ文法となります。
近年はビジネス部門でも業務用データベースからSQLを使ってデータ抽出する機会も増えてきているので、初心者向けにSQLの構文の解説をしたいと思います。
記事の内容
- テーブル定義(CREATE文)
- テーブル削除(DROP文)
- データ抽出 (SELECT文)
- データ挿入(INSERT文)
- データ更新(UPDATE文)
- データ削除 (DELETE文)
SELECT文については、FROM句でのテーブル結合や、GROUP BY句やWHERE句での条件指定方法等も触れます。
なお、初心者向けのSQLの構文の説明記事となりますので、データの正規化のようなテーブル設計に必要となる知識は範囲外です。
前提
関係データベースの製品について
この記事の例では、関係データベースはSQLite3を利用しています。SQLite3のセットアップや使い方は過去記事にしています。同じくSQLite3で試される方は参考にしてください。
MySQL等、他のデータベースを利用される場合でも問題ありません。細かい違いはあるものの、SQLの構文は基本的には同じです。
最近は、MongoDBのようなドキュメント・ベースのデータベースも流行っています。これらは関係データベースではないので、そもそもSQLが動きません。あくまで関係データベースを利用されることが前提になります。
記事内の表記ルールについて
SQLでは大文字と小文字が区別されません。この記事内では原則として、SQL固有のコマンドは全て大文字とし、テーブル名、列名は全て小文字で表記します。。
用語の説明
関係データベース関連の用語の説明です。
・ 関係データベース(RDB)
Relational Databaseの頭文字をとって、RDBとも呼ばれます。データを二次元の表形式で表すデータベースです。エクセルの表みたいなものをイメージしていただければ良いと思います。
・ SQL
関係データベースの操作を行う言語です。Structured Query Languageの略です。テーブルの定義や、データの抽出、挿入、更新等、データベースに関する操作はSQLで実行することになります。
余談ですが、英語では「エス・キュー・エル」ではなく「シークェル(すぃーくぅぉ)」と発音することが多いようです。英語の解説動画を見る際は、意識して(?)聞いてみてください。
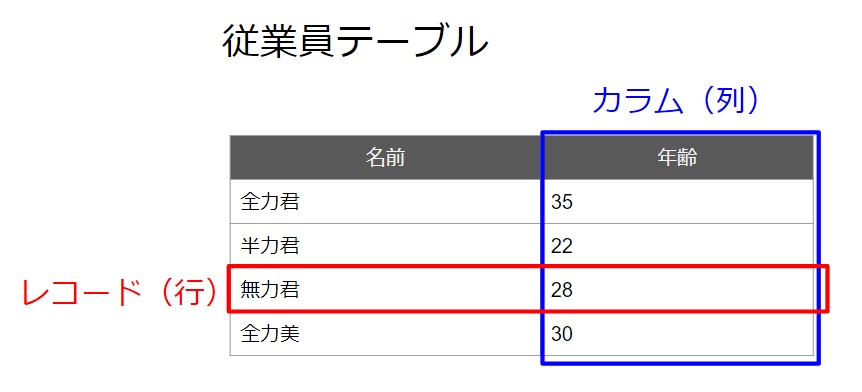
・ テーブル、カラム、レコード
テーブルはデータが格納される表です。予め表の項目を定めてテーブルを定義する必要があります。エクセルの表のイメージです。
カラムは、テーブルの項目のことです。日本語で「列」と言ったりします。
レコードは、テーブルに格納されているデータのことです。「行」と言ったりします。
・ CRUD
Create(作成)、Read(読み取る)、Update(更新)、Delete(削除)の頭文字をとってCRUDと呼びます。
ソフトウェアの設計等にも使われる概念ですが、SQLでCRUDと言えば概ね以下の意味で使われます。
- C: テーブルの作成(CREATE文)
- R: データの抽出(SELECT文)
- U: データの更新(UPDATE文)
- D: レコードの削除(DELETE文)、テーブルの削除(DROP文)
CREATE文
CREATE文はテーブルの定義を行います。データベースにデータを格納する前に、まずはデータ(レコード)を格納する箱として、テーブルを定義する必要があります。
構文
CREATE TABLE テーブル名 (列名1 型 制約, 列名2 型 制約,...);のように記述します。
型は、SQLite3ならINTEGER(整数)、REAL(浮動小数)、TEXT(文字列)等が指定できます。型はデータベース製品で差が出ると思います。例えば、OracleならCHAR(固定長文字列)やVARCHAR(可変長文字列)等があります。
SQL分の区切りを示すために、最後の";"は必要です。これも製品や環境によりますが、基本は必要なものと思ってください。
例
部署ID(整数)、部署名(文字列)の2列をもった、「部署マスタ」(division_master)テーブルの作成例です。部署IDにはPRIMARY KEY制約をつけます。
CREATE TABLE division_master (
id INTEGER PRIMARY KEY,
name TEXT
);
制約(constraint)
制約は、主要なものは以下のとおりです。
- PRIMARY KEY制約(主キー制約)
- UNIQUE制約
- NOT NULL制約
- FOREIGN KEY制約(外部キー制約)
制約は基本は任意ですが、PRIMARY KEYが必須となる製品もあります。
PRIMARY KEY(主キー)制約
PRIMARY KEYを付けた列は、テーブル内で同じ値の重複が許されません。必ず一意の値である必要があります。もし同じ値のデータを登録しようとすると、エラーになります。複数列の組み合わせでPRIMARY KEY制約を付けることも可能です。この制約がついた列は、自動的にNOT NULL制約がつきます。
PRIMARY KEYをつけた列は、値の重複がないことが保証されます。
複数の列の組み合わせでPRMARY KEYを設定することは出来ますが、PRIMARY KEYは1つのテーブルに1つしか設定できません。
UNIQUE制約
UNIQUE制約付けた列は、値の重複は許されません。PRIMARY kEY制約同様、複数列の組み合わせで指定することも可能です。
PRIMARY KEYに似ていますが、違いは以下のとおりです。
- NOT NULL制約はつかない。nullなら重複は可能。
- 1つのテーブルで、複数のUNIQUE制約を付けることが可能
NOT NULL制約
NOT NULL制約を付けた列は、必ず値を設定してデータを登録する必要があります。値が設定されている(NULLでない)ことが保証されます。
FOREIGN KEY 制約
ここは少し分かりにくいかもしれません。
例えば、「部署マスタ」というテーブルがあったとします。そして、「従業員」テーブルに「部署ID」という列があり、「部署マスタ」の「部署ID」列と同じ値が設定されるものとします。
ここで、「従業員」テーブルの「部署ID」列に、「部署マスタの部署IDを外部参照する」という制約の設定が出来ます。これがFOREIGN KEY制約です。そうすると、「従業員」テーブルにデータを登録・更新するときに、「部署マスタ」に存在しない「部署ID」を登録しようとすると、エラーになります。
各制約の例
制約がついたテーブルのCREATE文の例を見てみます。以下の「勤怠」(attendance)テーブルがあったとします。
- 日付(work_day) 文字列型 PRIMARY KEYの一部
- 従業員ID(employee_id)整数型 PRIMARY KEYの一部
- 休暇(vacation)整数型 NOT NULL制約
- 部署ID(division_id)整数型 部署マスタ(division_master)の部署ID(id)を参照するFOREIGN KEY制約
- 実働時間(work_hour)整数型
PRIMARY KEYも複数列の組み合わせになっています。
CREATE TABLE attendance (
work_day TEXT,
employee_id INTEGER,
vacation INTEGER NOT NULL,
division_id INTEGER,
PRIMARY KEY(work_day,employee_id)
FOREIGN KEY(division_id) references division_master(id)
);
制約は、上記例のPRIMARY KEYやFOREIGN KEYのように、列定義とは分けて個別に記述することも出来ます。
INSERT文
INSERT文でテーブルにデータ(レコード)を挿入します。
構文
文法はINSERT INTO テーブル名 (列名1,列名2,...)VALUES(値1,値2,...),(値3,値4),...;です。
テーブル名の後の「(列名1,列名2,...)」はデータを登録する列名です。指定しなかった列はNULLが設定されます。つまり、PRIMARY KEYやNOT NULL制約をつけている項目は、必ず指定する必要があります。また、全ての列に対してデータを登録する場合は、この「(列名1、列名2,...)」の部分は省略可能です。
VALUESの後の、「(値1,値2,...)」は、「(列名1,列名2,...)」で指定した列に対して、実際に登録する値となります。複数のレコードを挿入する場合は、「(値1,値2,...),(値3,値4),...」のようにカンマで区切って指定できます。
例
CREATE文の例で作った、division_masterテーブルについて、以下のデータを追加する例を見てみます。
id name
-- --------------
1 Sales
2 MARKETING
3 Human Resource
INSERT文は以下のようになります。
INSERT INTO division_master (id,name)
VALUES
(1,'Sales'),
(2,'MARKETING'),
(3,'Human Resource');
DELETE文
DELETE文はテーブルに登録されたレコードを削除する時に使います。
構文
DELETE FROM テーブル名 WHERE 条件のようにつかいます。条件には、「id=1」のように、基本的には「列名=値」のように指定します。WHERE句での条件指定はSELECT文と同じなので、詳細はそちらで解説します。
WHEREを省略すると、そのテーブルの全てのレコードが削除されます。テーブルの定義は残ります。
一部の製品だと、全てのレコードを削除する場合は、TRUNCATE文を使うのが一般的なようです。こちらは、TRUNCATE TABLE テーブル名と記述します。ちなみに、今回私が使っているSQLite3では、TRUNCATE文はサポートされていません。
例
INSERT文の例のdivision_masterテーブルから、idが2のレコードを削除する例です。
削除前は以下の3レコードが入っています。
id name
-- --------------
1 Sales
2 MARKETING
3 Human Resource
削除するSQLです。
DELETE FROM division_master WHERE id=2;
実行すると、idが2のMARKETINGのレコードが削除されていることが確認できます。
id name
-- --------------
1 Sales
3 Human Resource
DROP文
DROP文は、テーブルに登録されたレコードだけでなく、テーブルの定義ごと削除します。
構文はDROP TABLE テーブル名です。
SELECT文
SELECT文でデータ抽出をします。
構文
構文は、SELECT 列名1,列名2,... FROM テーブル名 WHERE 条件です。
SELECT直後の「列名1,列名2,...」に抽出したい列名を指定します。全ての列を抽出する場合、アスタリスク(「*」)で代替することができます。
WHERE直後の条件は、「division='sales' AND age=22」のように、抽出したいレコードの条件を指定します。WHEREを省略した場合、全てのレコードが抽出対象となります。
SELECT句は「列の指定」、WHERE句は「行(レコード)の指定」と、エクセルのような表をイメージすると分かりやすいと思います。
他にも、複数のテーブルを結合したり、合計や平均を求めたり、いろいろできますので、後述します。
WHERE句
テーブルからレコードを抽出する条件を指定するのがWHERE句です。ここでの指定の仕方を例で見てみます。なお、WHERE句に限った話ではありませんが、SQLで文字列の値を指定する場合、シングルクォーテーション(')で囲む必要があります。
例で使用するemployeeテーブルは以下の想定です。
id name division_id since
-- ----- ----------- ----------
1 John 1 2015-04-01
2 Beth 1 2018-12-01
3 Bob 1 2019-02-01
4 Kate 2 2015-04-01
5 Kayla 3 2015-04-01
- 等しい
SELECT * FROM employee WHERE name = 'John';
- 等しくない
SELECT * FROM employee WHERE name != 'John';
- より大きい
SELECT * FROM employee WHERE since > '2018-12-01';
- 以上
SELECT * FROM employee WHERE since >= '2018-12-01';
- AND
複数列に対して条件を付けるときはANDで繋げます。
SELECT * FROM employee
WHERE since >= '2018-12-01' AND division_id = 1;
-複数条件指定
同一列に対する複数の条件指定は「IN」を使ってできます。
SELECT * FROM employee WHERE name IN ('John','Beth','Kayla');
- OR
SELECT * FROM employee
WHERE since > '2018-12-01' OR division_id = 2;
- 文字列の部分一致
SELECT * FROM employee
WHERE name LIKE 'J%n';
「%」は「任意の0文字以上」という意味になります。上の例だと、「John、Jn、Jooaaaiin」等がヒットします。
「_」で「任意の1文字」という使い方もできます。
FROM句:内部結合
複数のテーブルを結合し、そこから列を抽出することも出来ます。まずは内部結合をみていきます。
例えば、以下の2つのテーブルがあったとします。
- employeeテーブル
sqlite> SELECT * FROM employee;
id name division_id since
-- ----- ----------- ----------
1 John 1 2015-04-01
2 Beth 1 2018-12-01
3 Bob 1 2019-02-01
4 Kate 2 2015-04-01
5 Kayla 3 2015-04-01
- division_masterテーブル
sqlite> SELECT * FROM division_master;
id name
-- ---------------
1 Sales
2 Marketing
3 Human Resources
4 Compliance
division_masterテーブルには、Compliance部門がありますが、employeeテーブルにはCompliance部門に所属している人はいません。ここは少しポイントになってきます。
例えば、従業員の名前と、その人が所属している部署名を抽出したいとします。employeeテーブルには、従業員の名前(name列)と、所属部署のid(division_id列)はありますが、部署名はありません。 しかし、この所属部署のidの値は、division_masterテーブルのid列の値と同じです。そして、division_masterテーブルには、部署のidと、部署名どちらもあります。
employeeテーブルのdivision_idと、division_masterのid列を結合すれば、どちらも抽出することが可能です。
テーブル結合をする場合、以下のように記述します。
SELECT
e.name AS 従業員名,
d.name AS 部署名
FROM
employee AS e INNER JOIN division_master AS d
on e.division_id = d.id;
FROM句で、「テーブル名1 INNER JOIN テーブル名2」のように結合したいテーブルを記述します。 そのあと、「on 結合条件」と記述します。今回の例だと結合条件は「employeeテーブルのdivision_idとdivision_masterのidが等しい」となります。AND等で繋げて複数条件を指定することも可能です。
今回の例では使っていませんが、WHERE句を使って抽出するレコードに条件をつけることもできます。
結合と直接関係ありませんが、「AS」で、テーブル名や抽出した項目に別名をつけています。一部の製品では別名をつける際、「AS」の指定は不要なものもあります。 後、改行の位置は上のようにする必要はないので、見やすいところで改行してもらって大丈夫です。
検索結果は以下のようになります。
従業員名 部署名
----- ---------------
John Sales
Beth Sales
Bob Sales
Kate Marketing
Kayla Human Resources
division_masterには、「id:4 name:Compliance」のレコードがありましたが、employeeテーブルにはここに所属している人はいませんでした(employeeテーブルのdivision_idが4のレコードはありませんでした)。なので、検索結果には部署名がComplianceのデータは見当たりません。
内部結合では、結合条件で指定した項目で、片方のテーブルにしか存在しない値は抽出対象になりません。双方のテーブルに存在するものが抽出されます。
FROM句:外部結合
内部結合では、結合条件で指定した項目は、双方のテーブルに存在するもののにが抽出されました。片方のテーブルにしか存在しないレコードも抽出対象にしたい場合、外部結合を利用します。
内部結合の例では、division_masterのid列が4のレコードは、’employeeテーブルのdivision_idが4のレコードが存在しないため)抽出対象になりませんでした。 employeeテーブルでの存否に関わらず、division_masterにあるレコードは全て抽出したい場合、以下のように外部結合を記述します。
SELECT
e.name AS 従業員名,
d.name AS 部署名
FROM
employee AS e RIGHT OUTER JOIN division_master AS d
on e.division_id = d.id;
内部結合と違う部分は、「INNER JOIN」の部分が「RIGHT OUTER JOIN」に変わっているところです。右側の記述したdivision_masterのみ存在するレコードも抽出対象にするので、RIGHTです。逆に、左側に記述したテーブルのみに存在するレコードを抽出対象にしたい場合、「LEFT OUTER JOIN」になります。
実行結果は以下の通りです。
従業員名 部署名
----- ---------------
John Sales
Beth Sales
Bob Sales
Kate Marketing
Kayla Human Resources
Compliance
Complianceが抽出されているのが分かります。従業員名(employeeのname列)は何も設定されていません。これはemployeeテーブルにはdivision_idが4のレコードはないためです。
完全外部結合
「LEFT OUTER JOIN」や「RIGHT OUTER JOIN」は片方のテーブルにしか存在しないレコードも抽出対象にします。結合する項目が、左側のテーブルにしか存在しない値、右側のテーブルにしか存在しない値がそれぞれあり、どちらも抽出したい場合、「FULL OUTER JOIN」を使います。完全外部結合といいます。ただし、あまり使う機会は無いと思いますし、MySQLのように一部の製品ではサポートされていません。
GROUP BY句
テーブルの行単位ではなく、特定の列で集約し、最大値や平均値等を計算することもできます。集約する列(もしくは列の組み合わせは)は、GROUP BY句で指定できます。GROUP BY 列名1,列名 2,...のように記述します。
以下のsalesテーブルがあったとします。
sold_date employee_id seq price
---------- ----------- --- -----
2023-04-01 1 1 50000
2023-04-01 1 2 15000
2023-04-05 2 1 1000
2023-04-10 2 1 1000
2023-04-10 3 1 10000
例えば、ここで日付(sold_date)ごとの売上(price)の合計を出したいとします。
SELECT
sold_date 売上日,
SUM(price) 合計売上
FROM sales
GROUP BY sold_date
sold_dateでグループ化し、その単位でpriceの合計を取得しています。この例では出てきませんが、もちろん内部(外部)結合やWHERE句と組み合わせることも出来ます。 GROUP BYは、FROMやWHERE等で導出された表に対して適用されます。
「SUM(列名)」は集計関数と呼ばれるものです。他にも、以下のような集約関数があります。
- COUNT(*) :レコード数
- AVG(列名):平均
- MAX(列名):最大値
- MIN(列名):最小値
また、GROUP BYを使用した場合、SELECT句で選択できる項目は、GROUP BYで指定した列と、集約関数に限られます。上の例だと、sold_date列と、SUMのような集約関数は利用できますが、例えばemployee_idのような他の列名は使用することは出来ません。項目を指定して集約しているので、自然と言えば自然ですかね。ただし、一部の製品ではエラーにはならない場合もあります。
最後に
SQLの基礎的な構文について解説しました。サブクエリや、EXISTS句等、今回触れられていない機能もありますが、こちらは今回紹介した機能と比べると、少し応用的な内容になるかと思います。 実際に書いて覚えるのが一番の近道だと思うので、いろいろ試していただければと思います。